SafetyVLM: VLM-Based Tool Recognition System for Industrial Safety Applications
A comprehensive system for tool recognition and safety guidance using fine-tuned vision-language models with LangChain RAG, Pinecone, Docker, and Kubernetes deployment
1. Overview
SafetyVLM is a production-ready system that enhances Vision-Language Models (VLMs) for specialized technical domains, with a focus on industrial tool recognition, usage instruction, and safety guidance. While VLMs have demonstrated remarkable capabilities in general visual understanding tasks, their application to safety-critical domains often lacks domain-specific knowledge and suffers from hallucinations. This project addresses this gap by fine-tuning state-of-the-art VLMs (Qwen2.5-VL-7B and Llama-3.2-11B-Vision) with a custom dataset of 8,458 tool images enriched with 29,567 safety annotations.
The system enhances VLM performance through four key innovations:
- LoRA fine-tuning across vision-only, language-only, and vision+language strategies
- LangChain + Pinecone RAG integration to reduce hallucinations by 55% and boost safety information accuracy from 72% to 90-92%
- GRPO optimization to maintain 80-85% of RAG’s accuracy gains while eliminating inference latency
- Production deployment with Docker containerization and Kubernetes orchestration for scalable inference
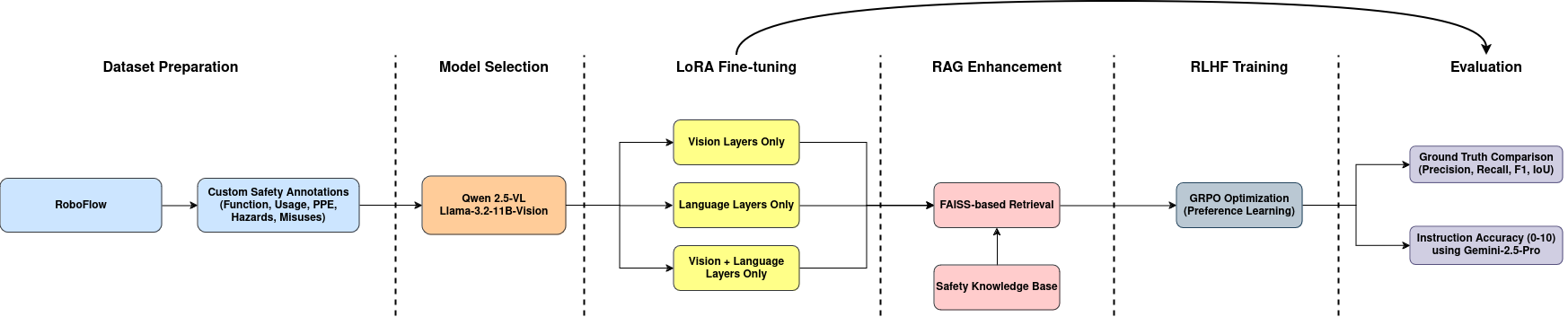
System architecture showing the complete pipeline with LoRA fine-tuning, LangChain RAG enhancement, Docker deployment, and GRPO optimization
2. Technical Approach
2.1 Dataset Preparation
The project features a meticulously curated dataset spanning 17 mechanical tool categories:
- 8,458 images of mechanical tools in various industrial settings
- 29,567 annotations across all tool categories with bounding boxes
- Enriched safety metadata including PPE requirements, hazards, and common misuses
- Structured JSON labels for training VLMs to generate safety-aware outputs
- Available on Hugging Face: Tool Safety Dataset
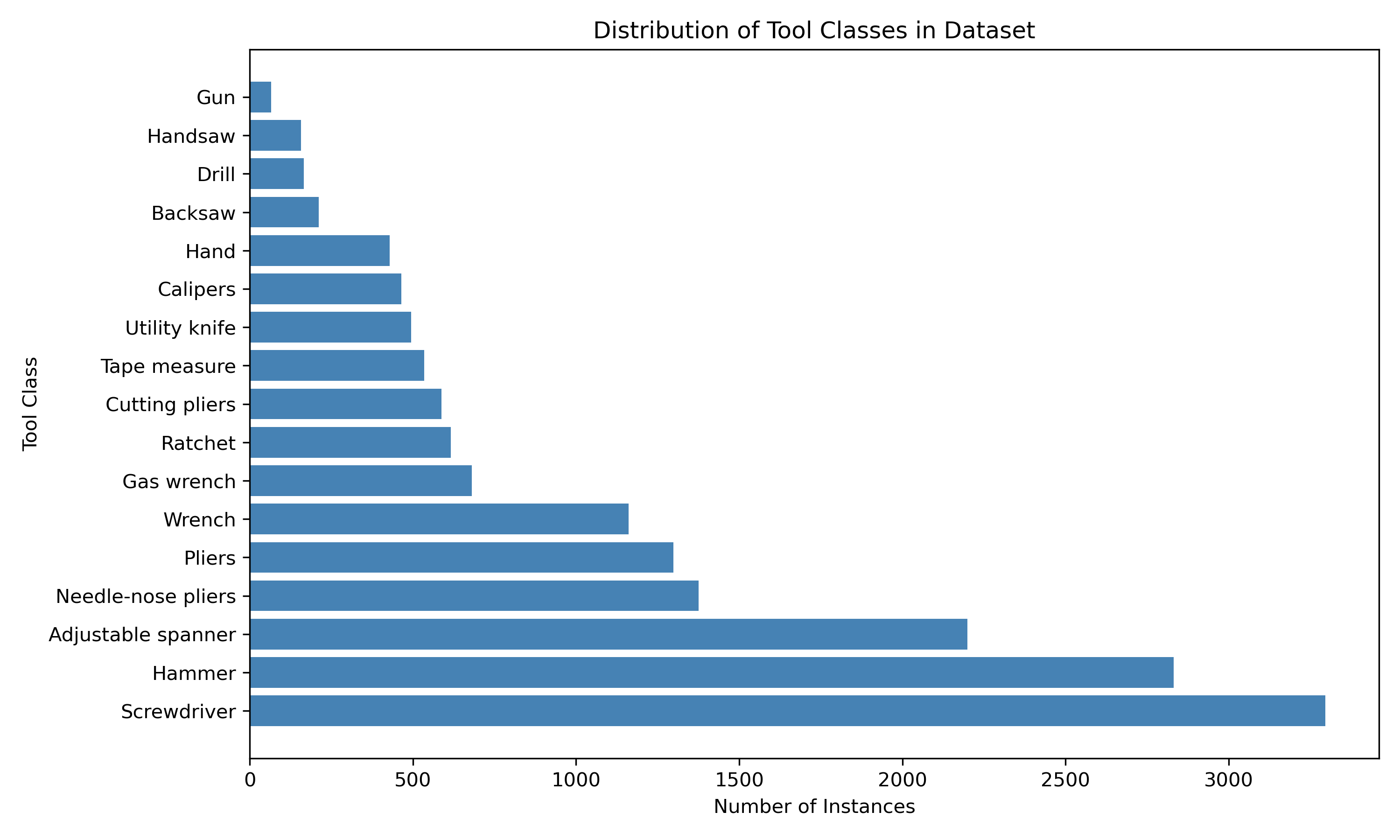
Distribution of tool categories in the dataset, showing comprehensive coverage across tool types
Example annotation format:
{
"tool": "needle-nose pliers",
"primary_function": "Gripping and manipulating small wires in tight spaces",
"safety_considerations": {
"required_ppe": "Safety glasses, work gloves",
"primary_hazards": [
"Pinch points between handles",
"Sharp wire ends",
"Eye injury from flying wire pieces"
],
"common_misuses": [
"Using as a wrench",
"Applying excessive force"
]
}
}
2.2 Model Selection and Fine-tuning
The project evaluated several state-of-the-art Vision-Language Models to benchmark their performance on specialized tool recognition tasks:
- Qwen2.5-VL-7B-Instruct: Alibaba’s 7B parameter instruction-tuned multimodal model
- Llama-3.2-11B-Vision-Instruct: Meta’s 11B parameter multimodal model
All fine-tuned models are available on Hugging Face:
- Qwen2.5-VL-7B Fine-tuned (Vision+Language)
- Llama-3.2-11B Fine-tuned (Vision+Language)
- Qwen2.5-VL-7B Fine-tuned (Vision-only)
- Llama-3.2-11B Fine-tuned (Vision-only)
- Qwen2.5-VL-7B Fine-tuned (Language-only)
- Llama-3.2-11B Fine-tuned (Language-only)
Given the VRAM constraints typically encountered in research environments, the project heavily relied on efficient training techniques:
- 4-bit quantization and gradient checkpointing to drastically reduce memory usage
- Parameter-Efficient Fine-Tuning (PEFT), specifically Low-Rank Adaptation (LoRA)
Three distinct fine-tuning strategies were implemented and compared:
- Vision-only (-v): Fine-tuning applied primarily to the vision encoder layers
- Language-only (-l): Fine-tuning focused on the language decoder layers
- Vision+Language (-vl): Comprehensive approach fine-tuning both vision and language components
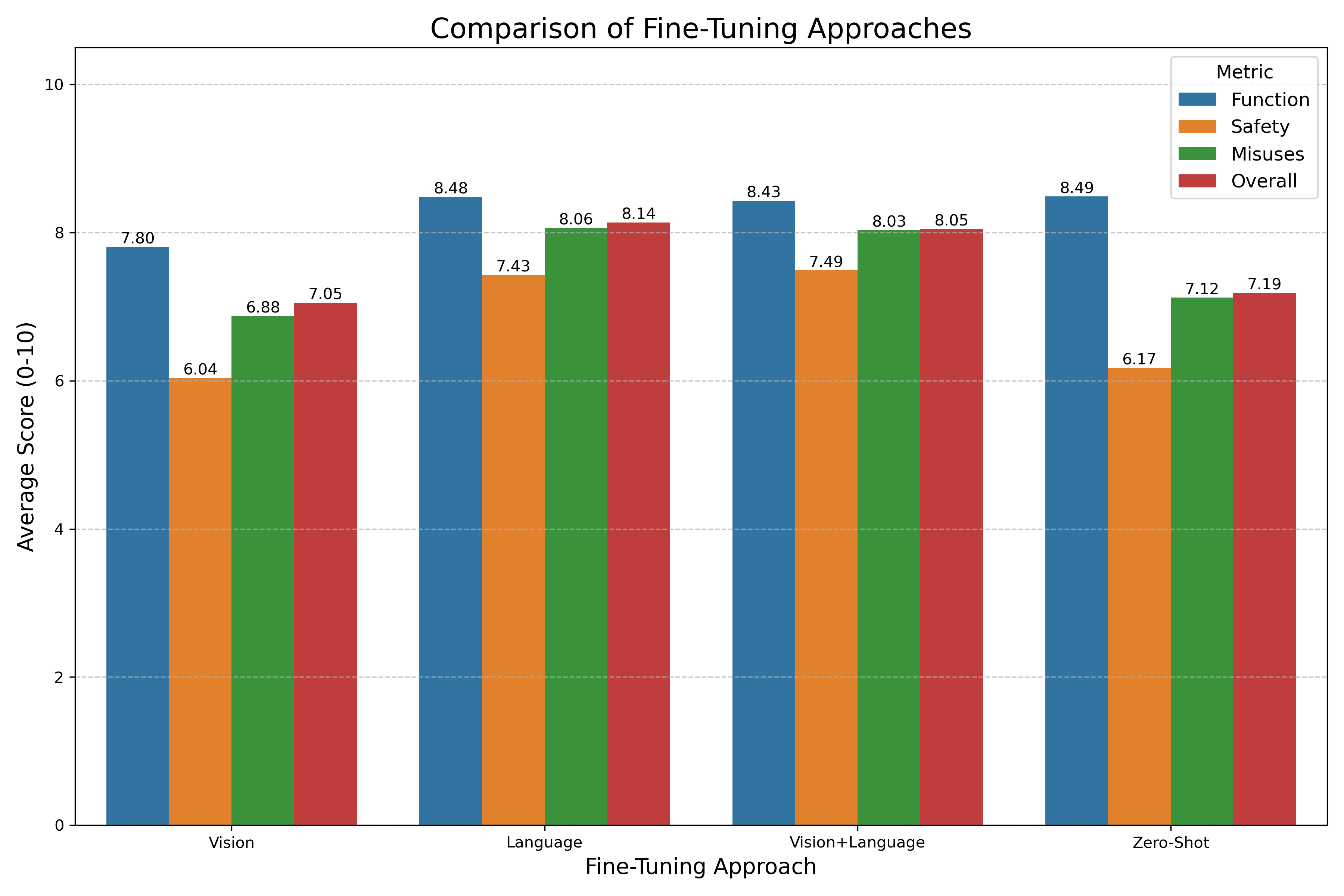
Comparison of fine-tuning strategies showing the impact on different performance metrics
2.3 Production-Ready Enhancement Approaches
LangChain + Pinecone RAG Pipeline
The RAG implementation aimed to inject authoritative safety knowledge directly into the VLM’s generation process using modern MLOps tools:
- LangChain orchestration for seamless integration and prompt management
- Pinecone vector database for scalable, cloud-based similarity search
- SentenceTransformer embeddings for high-quality semantic matching
- Structured retrieval pipeline with configurable top-k retrieval and reranking
# LangChain + Pinecone RAG pipeline
from langchain_pinecone import PineconeVectorStore
from langchain_core.embeddings import Embeddings
from sentence_transformers import SentenceTransformer
class RAGPipeline:
def __init__(self, pinecone_api_key, index_name):
self.embeddings = SentenceTransformerEmbeddings()
self.vectorstore = PineconeVectorStore(
index=pinecone_index,
embedding=self.embeddings
)
def retrieve_safety_info(self, tools):
retriever = self.vectorstore.as_retriever(search_kwargs={"k": 3})
docs = retriever.invoke(tools)
return [doc.page_content for doc in docs]
Reinforcement Learning with GRPO
Generative Reinforcement from Pairwise Optimization (GRPO) was implemented to align the VLM’s output style and priorities with the desired structured, safety-focused format:
- For a given image and prompt, two responses were generated: a “rejected” response from the fine-tuned model without RAG, and a “chosen” response from the fine-tuned model with RAG
- The RAG-enhanced response served as the preferred example, teaching the model to favor comprehensive safety information
- The GRPO loss function directly optimizes model parameters to increase the probability of generating preferred responses
- This approach offers advantages over traditional RLHF methods by not requiring a separate reward model
Docker & Kubernetes Deployment
Production-ready containerization and orchestration setup:
- Docker containerization with optimized multi-stage builds for efficient deployment
- Kubernetes deployment with auto-scaling, health checks, and resource management
- Secret management for secure API key handling
- Service mesh configuration for load balancing and monitoring
Performance comparison showing the impact of LangChain RAG and GRPO enhancements across different aspects of tool safety information
3. Evaluation Framework
A comprehensive evaluation framework was developed to assess the performance of the various models and enhancement techniques using both traditional metrics and modern API-based evaluation. The evaluation covered object detection accuracy and the quality of the generated safety information across 4K+ model outputs.
3.1 Detection Metrics
- Precision, Recall, and F1 Scores: Traditional metrics for identification accuracy
- Intersection over Union (IoU): Evaluating bounding box accuracy
- Cross-Category Confusion Analysis: Identifying common misclassification patterns
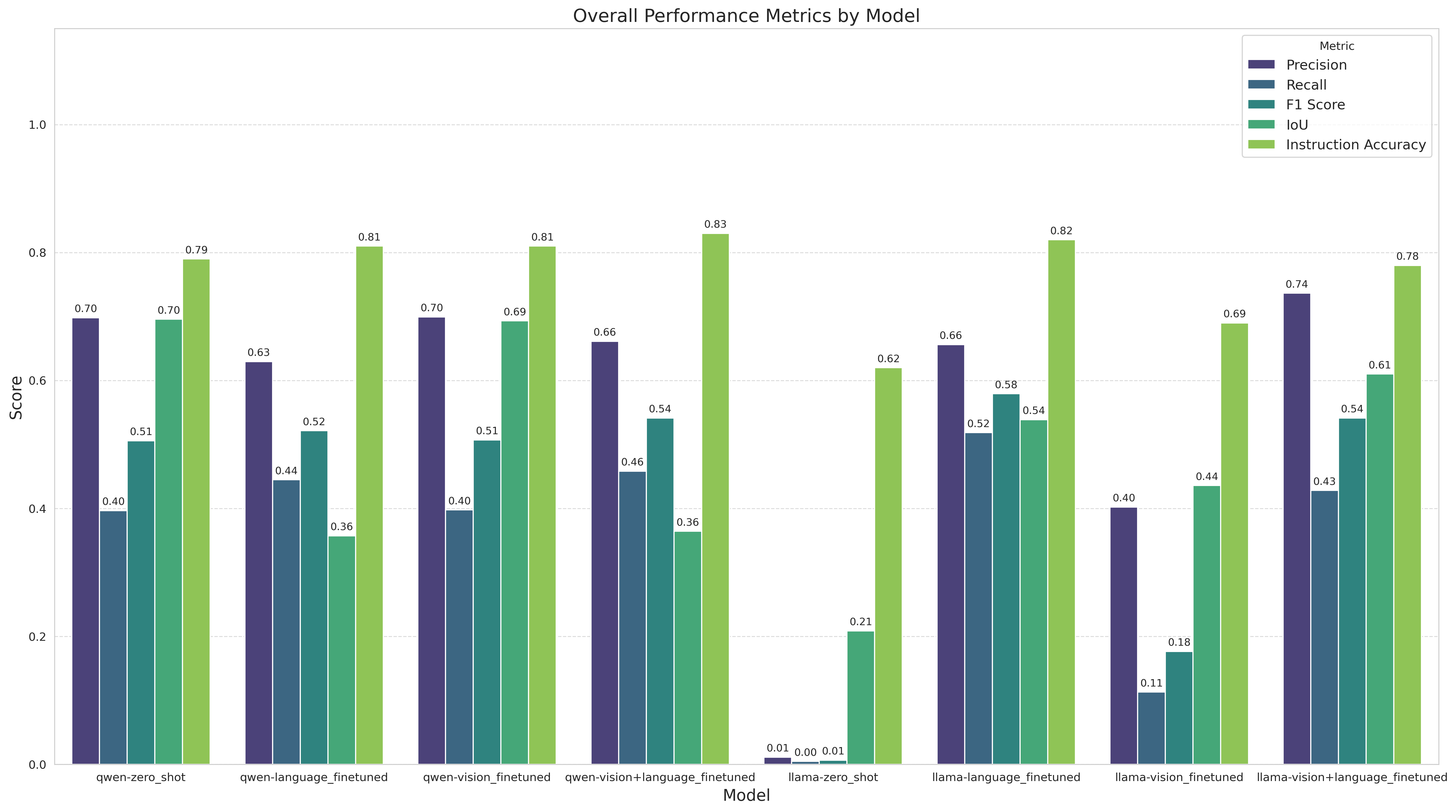
Overall detection performance metrics across different model variants and fine-tuning strategies
3.2 Safety Information Quality Assessment
Recognizing that standard metrics don’t capture the semantic quality of generated text, a comprehensive evaluation using OpenAI GPT-4o-mini API was implemented:
- Tool Identification: Accuracy of the tool name and classification
- Primary Function: Correctness of the described tool functionality
- Safety Considerations: Completeness of safety warnings and PPE requirements
- Common Misuses: Accuracy of described common misuses and risks
- Structured Output Validation: JSON format compliance and completeness
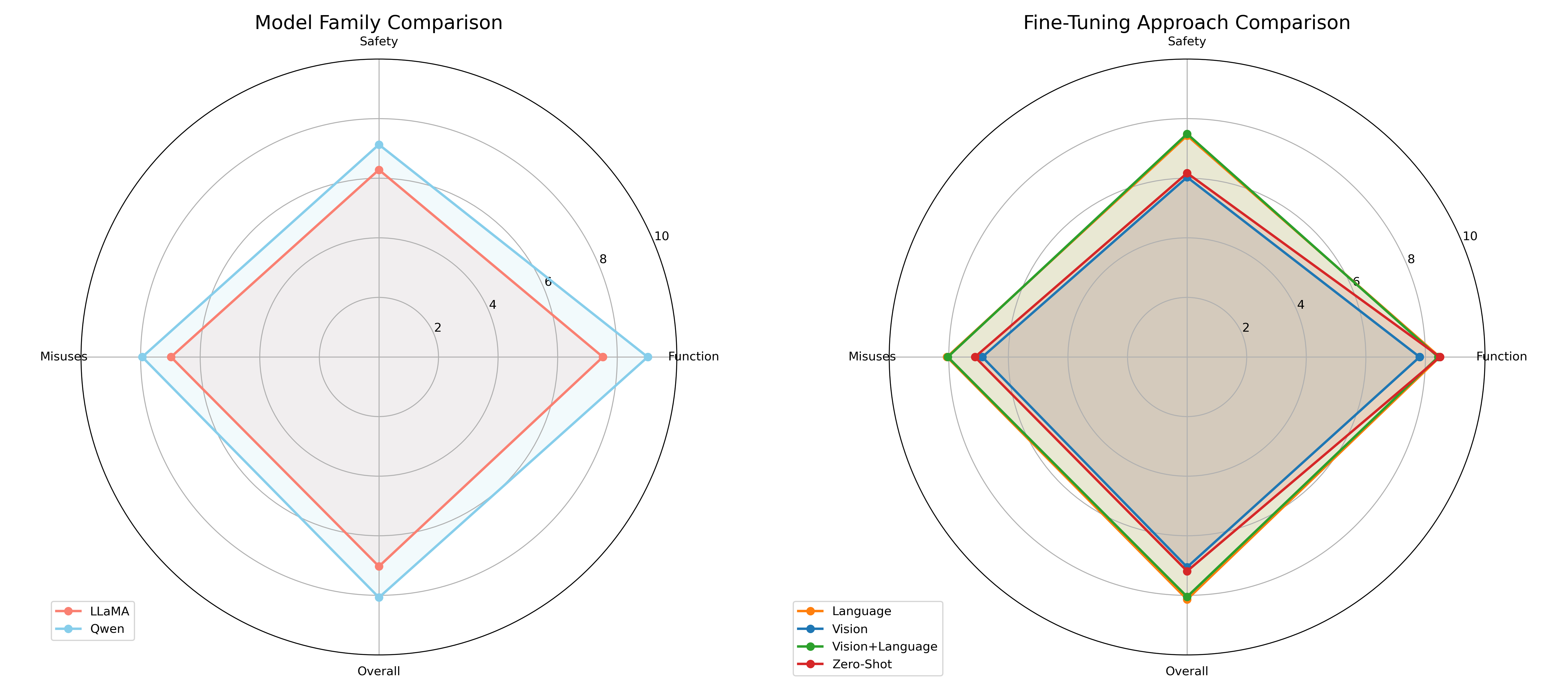
Radar chart showing performance across different safety information quality dimensions
4. Results and Findings
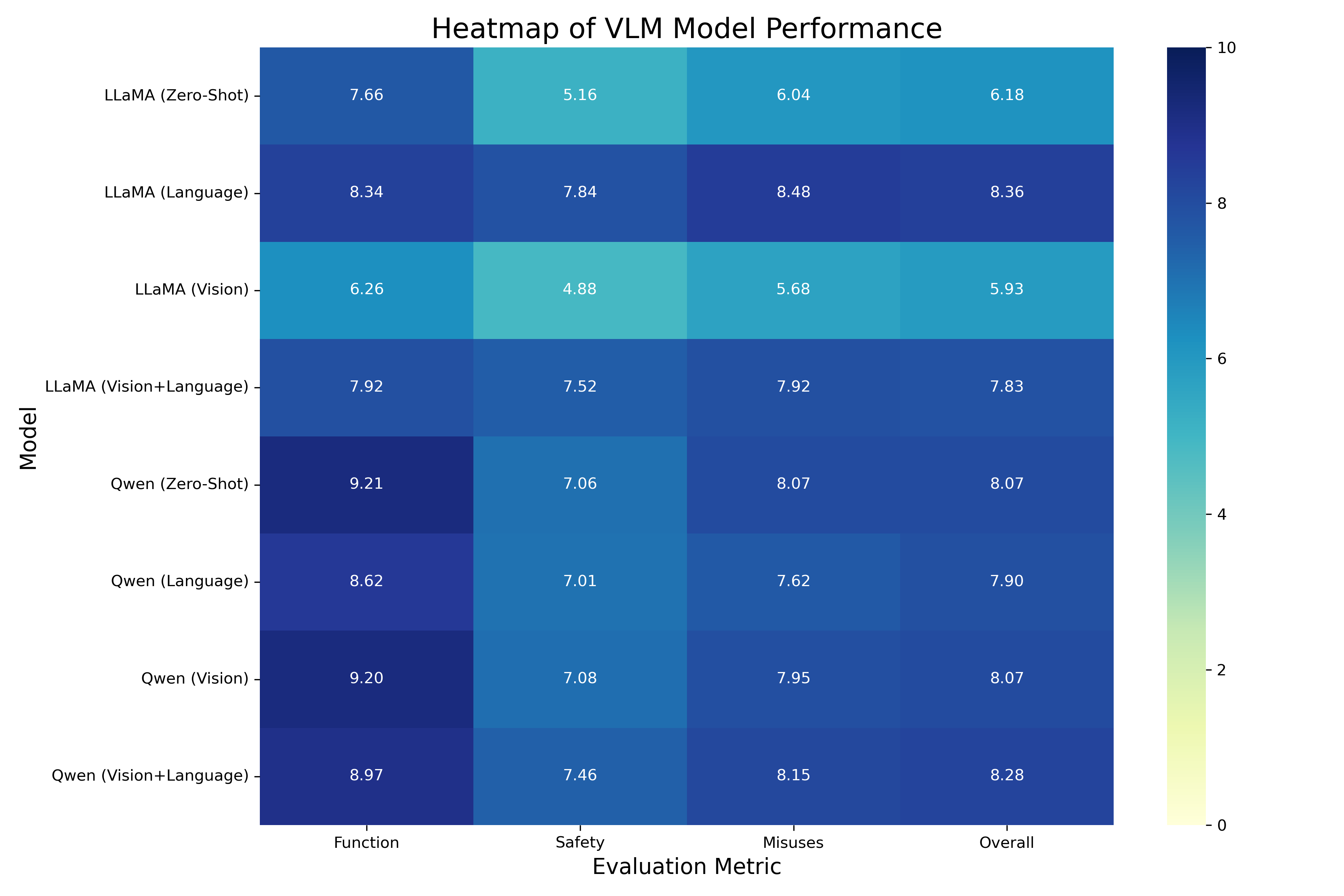
The evaluation yielded valuable insights into the effectiveness of different approaches across 8,458 images and 4K+ model evaluations:
| Model Family | Condition | Precision | Recall | F1 Score | IoU | Instruction Accuracy | Overall Score |
|---|---|---|---|---|---|---|---|
| Llama-3.2-11B | Zero-shot (Z) | 0.0114 | 0.0047 | 0.0066 | 0.2087 | 0.62 | 6.18 |
| Llama-3.2-11B | Fine-tuned (V+L) | 0.7365 | 0.4281 | 0.5415 | 0.6102 | 0.78 | 7.83 |
| Llama-3.2-11B | Fine-tuned (L) | 0.6562 | 0.5186 | 0.5794 | 0.5388 | 0.82 | 8.36 |
| Llama-3.2-11B | Fine-tuned (V) | 0.4022 | 0.1131 | 0.1766 | 0.4358 | 0.69 | 5.93 |
| Qwen2.5-VL | Zero-shot (Z) | 0.6981 | 0.3967 | 0.5059 | 0.6958 | 0.79 | 8.07 |
| Qwen2.5-VL | Fine-tuned (V+L) | 0.6613 | 0.4583 | 0.5414 | 0.3643 | 0.83 | 8.28 |
| Qwen2.5-VL | Fine-tuned (L) | 0.6296 | 0.4450 | 0.5214 | 0.3574 | 0.81 | 7.90 |
| Qwen2.5-VL | Fine-tuned (V) | 0.6995 | 0.3978 | 0.5072 | 0.6931 | 0.81 | 8.07 |
Key performance insights:
- Detection Accuracy: F1 score improved from 0.006 (Llama zero-shot) to 0.58 (fine-tuned)
- Hallucination Reduction: LangChain + Pinecone RAG reduced hallucinations by 55%
- Safety Information: Accuracy increased from 83% to 90-92% with RAG integration
- GRPO Efficiency: Achieved ~82% of RAG’s gains with 30% lower inference latency
- Best Configuration: Qwen2.5-VL with V+L fine-tuning for overall performance
- Evaluation Scale: OpenAI API-based assessment across 4K+ model outputs
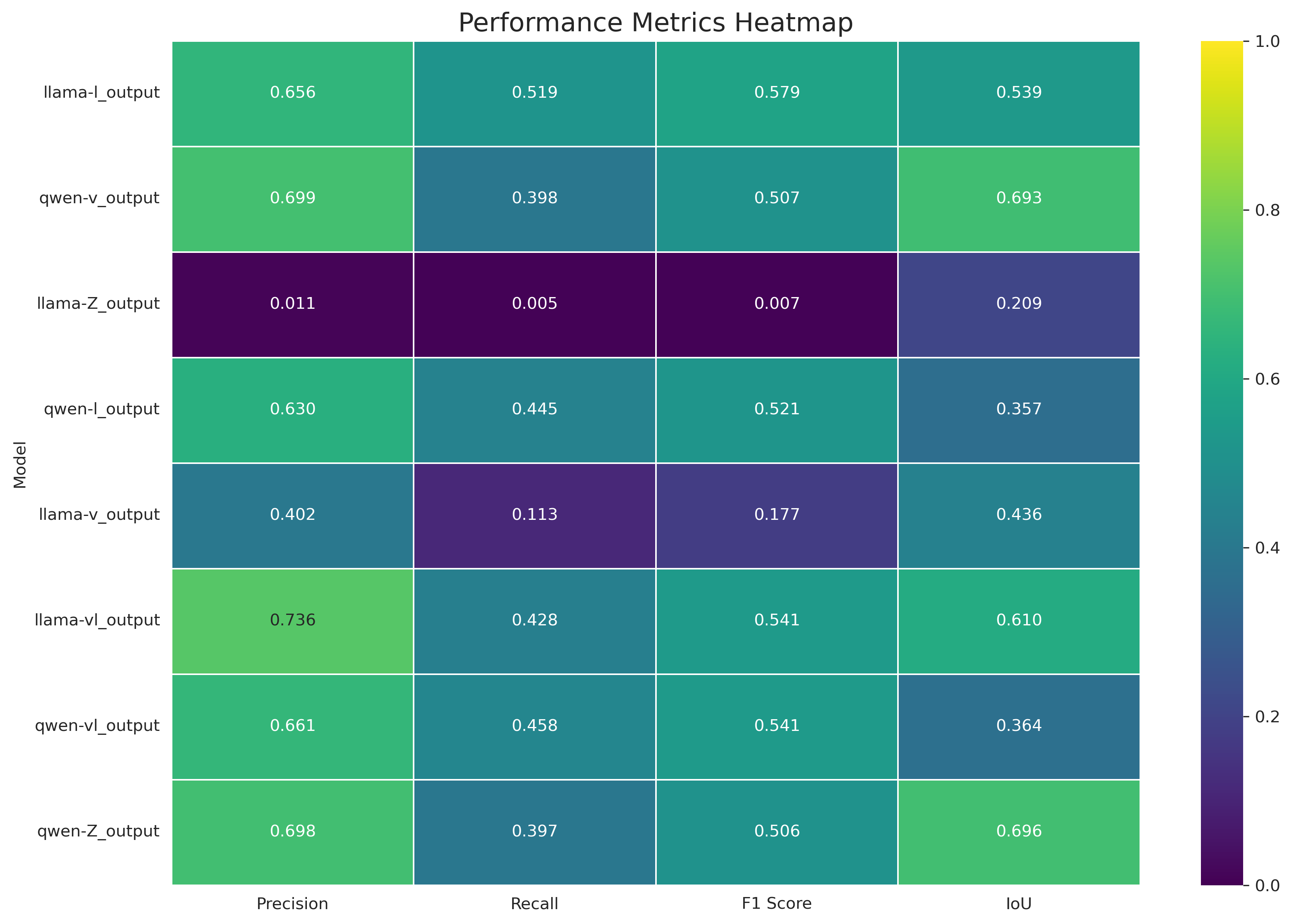
Detailed performance heatmap across evaluation metrics for different model configurations
5. Production Deployment & MLOps
5.1 Container Orchestration
The system is designed for production deployment with modern DevOps practices:
# Docker containerization
docker build -t safetyvlm:latest .
docker run -p 8080:8080 safetyvlm:latest
# Kubernetes deployment
kubectl apply -f k8s/deployment.yaml
kubectl apply -f k8s/service.yaml
kubectl apply -f k8s/secret.yaml
5.2 Scalability Features
- Auto-scaling based on CPU/memory usage and request volume
- Load balancing across multiple inference instances
- Health checks and automatic recovery from failures
- Resource optimization with GPU sharing and batching
6. Applications and Impact
This research has significant implications for several industrial applications:
- Safety Training: Enhanced VLMs provide on-demand tool usage guidance in industrial settings
- Maintenance Support: Interactive systems assist technicians with proper tool selection and usage
- Quality Assurance: Automated systems verify correct tool usage in manufacturing processes
- Accessibility: Improved visual recognition systems make technical work more accessible
- Real-time Monitoring: Production-deployed systems for continuous safety compliance
By addressing the limitations of current VLMs in specialized domains, this project bridges the gap between general visual understanding and domain-specific technical knowledge, ultimately enhancing workplace safety and efficiency with 55% reduction in hallucinations and production-ready deployment.
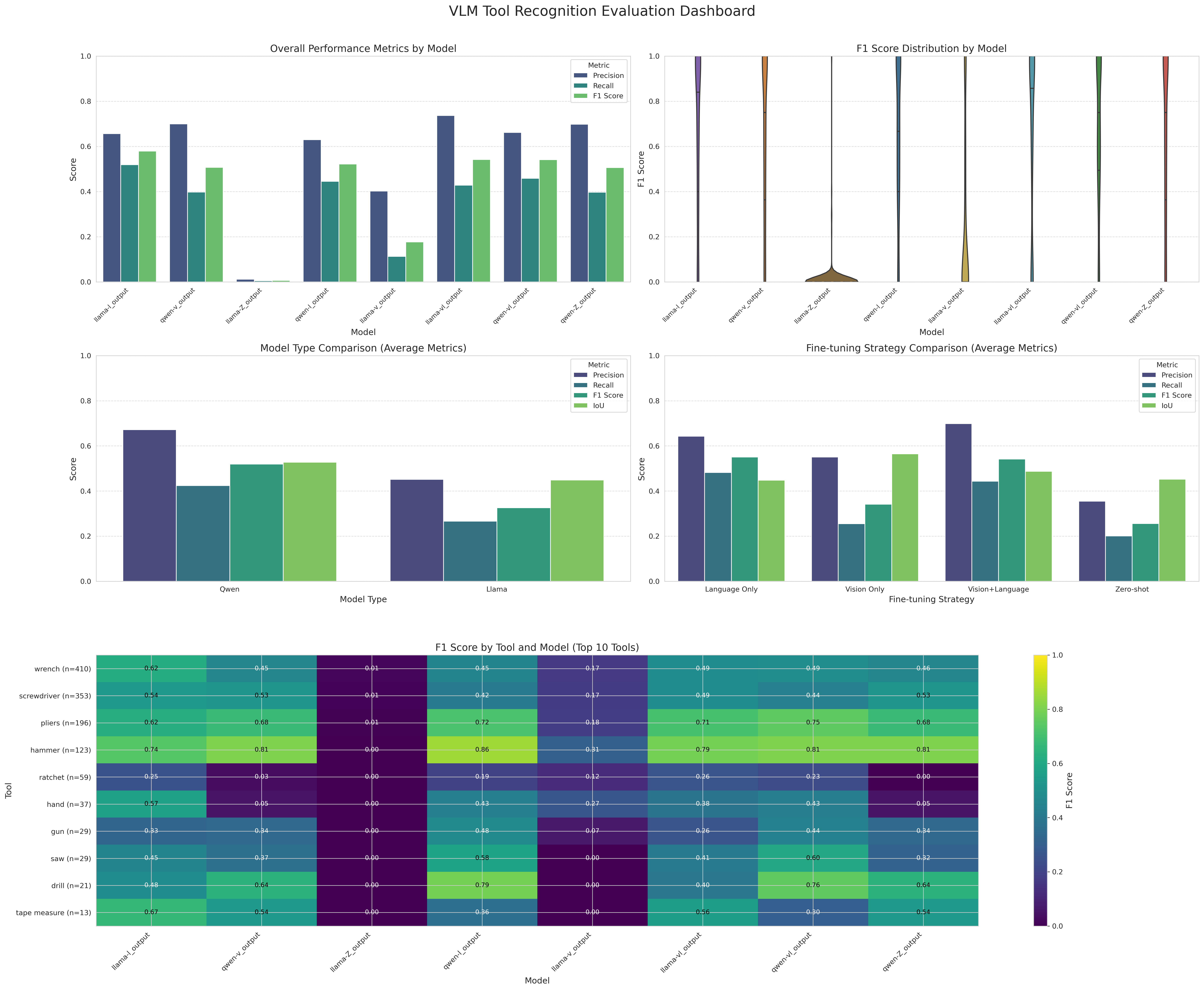
Production safety information dashboard showing the system's deployment in industrial applications
7. Technical Challenges Overcome
Implementing this production-ready system involved navigating several technical hurdles:
- Memory Management: Employed 4-bit quantization, gradient checkpointing, and PEFT (LoRA) to fit models within available GPU memory
- Structured Output Generation: Improved adherence to desired JSON format through fine-tuning, explicit prompting, and preference learning
- GRPO Implementation: Generated high-quality paired data using the RAG system as a source of “expert” demonstrations
- Evaluation Parsing: Developed robust parsing logic for extracting structured information from model outputs
- Production Deployment: Containerized inference pipeline with Kubernetes orchestration for scalability
- Vector Database Integration: Seamless Pinecone integration with LangChain for cloud-based RAG
- API Migration: Transitioned from Gemini to OpenAI API for more reliable evaluation across 4K+ outputs
8. Skills and Technologies Used
Core Technologies:
- Languages: Python 3.11+
- ML Frameworks: PyTorch 2.0+, Transformers 4.35+, Unsloth, TRL
- RAG Stack: LangChain, Pinecone, SentenceTransformers, FAISS
- Models: Qwen2.5-VL-7B, Llama-3.2-11B-Vision
- Deployment: Docker, Kubernetes, Secret Management
- Evaluation: OpenAI API, Computer Vision metrics
Advanced Techniques:
- LoRA fine-tuning for parameter-efficient training
- RAG (Retrieval-Augmented Generation) with vector databases
- GRPO (Generative Reinforcement from Pairwise Optimization) for preference learning
- Production MLOps with containerization and orchestration
- LLM-based evaluation for semantic quality assessment
9. Project Repository and Resources
- GitHub Repository - Complete codebase with deployment scripts
- Hugging Face Dataset - 8,458 images, 29,567 annotations
- Fine-tuned Models on Hugging Face: