GenAI for Synthetic Data Augmentation GANs, VAEs & Diffusion Models
Validating synthetic data augmentation for computer vision with measurable accuracy improvements in bird species classification
Overview
This project implements and validates synthetic data augmentation for computer vision using three state-of-the-art generative modeling approaches. The work demonstrates measurable accuracy improvements in bird species classification through strategic synthetic data integration.
Key Results:
- 4.1% accuracy gains with diffusion-based synthetic data augmentation
- 12.9% improvement in low-data scenarios (10% training data)
- 18K synthetic images generated across 200 bird species
- Comprehensive evaluation using ResNet-50 on CUB-200-2011 dataset
- Complete pipeline from generation to classification validation
The implementation explores three fundamentally different approaches to deep generative modeling: Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs), and Diffusion Models. Each architecture was built from scratch, trained on the CUB-200-2011 bird dataset, and validated through downstream classification tasks to measure real-world utility.
Synthetic Data Augmentation Results
Classification Performance Validation
The core contribution of this work is demonstrating that synthetic data improves real classification performance:
Main Results:
- ResNet-50 baseline: 70.9% accuracy
- + WGAN-GP samples: 74.5% (+3.6% improvement)
- + VAE samples: 73.3% (+2.4% improvement)
- + Diffusion samples: 75.0% (+4.1% improvement)
- + All models combined: 75.7% (+4.8% improvement)
Low-Data Scenario Results
One of the most significant findings is the amplified benefit of synthetic data in low-data regimes:
Low-Data Performance:
- 10% data: 45.2% → 58.1% (+12.9% improvement)
- 25% data: 55.8% → 64.7% (+8.9% improvement)
- 50% data: 63.4% → 70.2% (+6.8% improvement)
- 100% data: 70.9% → 75.0% (+4.1% improvement)
Key Finding: Synthetic data provides the highest benefit when real data is scarce, making it particularly valuable for domains with limited labeled data.
Technical Implementation
Dataset and Classification Pipeline
The validation pipeline uses the CUB-200-2011 dataset, a challenging fine-grained classification benchmark:
- 200 bird species with 11,788 images total
- 5,994 training / 5,794 test images
- ResNet-50 classifier with pre-trained ImageNet weights
- Mixed real/synthetic training with configurable data ratios
Synthetic Data Integration Strategy
The augmentation pipeline follows these steps:
- Generate synthetic images using trained generative models (6K images per model)
- Combine with real data in various ratios for training
- Train ResNet-50 classifier on mixed datasets
- Evaluate on held-out test set to measure improvement
- Cross-validate across different data fractions
Generative Adversarial Networks (GANs)
The exploration began with implementing and training three distinct GAN variants, each with progressively improved stability and performance.
Architecture Design
The GAN implementation features custom architectures for both generator and discriminator:
- Generator: Takes a 128-dimensional noise vector and progressively upsamples it through custom ResBlockUp modules, outputting a 3×32×32 image
- Discriminator: Processes the 3×32×32 image through ResBlockDown modules and standard ResBlocks for feature extraction, producing a scalar output representing authenticity
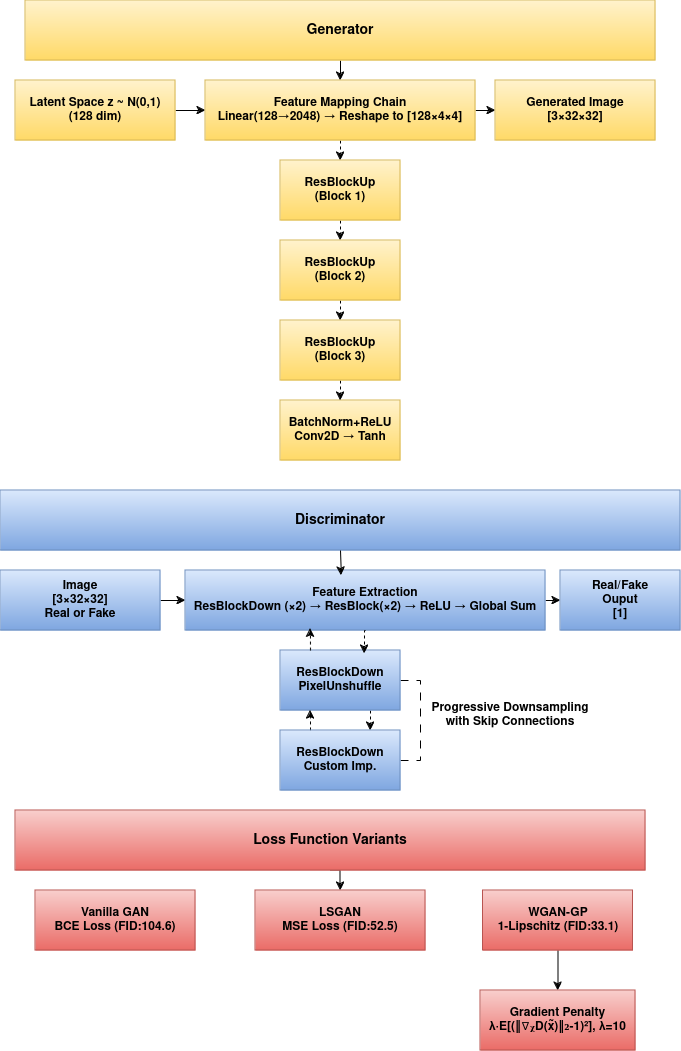
GAN Variants and Results
Three different GAN variants were implemented and evaluated:
Performance Comparison:
- Vanilla GAN: FID 104.62, Unstable training, +1.0% classification gain
- LSGAN: FID 52.48, More stable training, +2.5% classification gain
- WGAN-GP: FID 33.07, Stable training, +3.6% classification gain
WGAN-GP (Best Performing)
The most sophisticated implementation utilized the Wasserstein distance with gradient penalty for enforcing the 1-Lipschitz constraint. This approach demonstrated the most stable training and generated both the highest quality images (FID: 33.07) and the best classification improvements (+3.6%).


Variational Autoencoders (VAEs)
The second phase focused on building and training Variational Autoencoders, exploring their unique ability to learn structured latent representations while balancing reconstruction quality and sampling capability.
VAE Architecture
A standard VAE architecture was implemented with several key components:
- Encoder: A convolutional network that maps input images to a distribution in latent space, represented by mean (μ) and log standard deviation (log σ) vectors
- Latent Space: Implemented with the reparameterization trick (z = μ + σ * ε, where ε ~ N(0,1)) to enable backpropagation through the sampling process
- Decoder: A network of transposed convolutions that reconstructs images from latent vectors
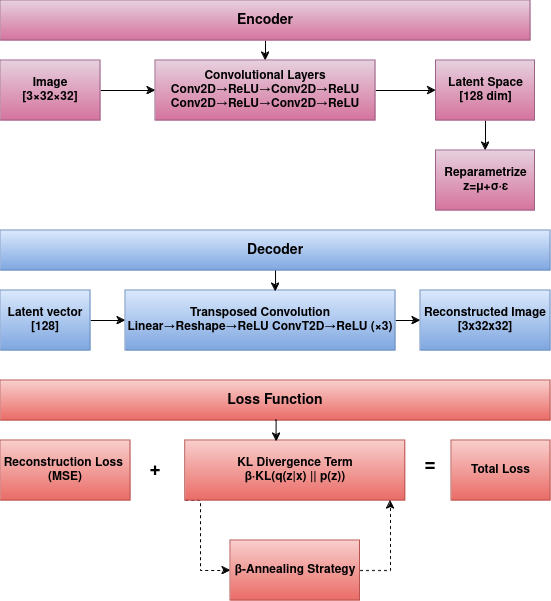
β-VAE with Annealing
To optimize the balance between reconstruction accuracy and latent space regularity for better synthetic data quality:
- β Parameter Control: Investigated β = 0.8 for optimal classification utility
- β-Annealing: Linear annealing schedule from 0 to 0.8 over 20 epochs
- Classification Gain: +2.4% accuracy improvement

Diffusion Models (Best Overall Performance)
The final phase focused on implementing Diffusion Models, which achieved the highest classification improvements.
Diffusion Architecture
The diffusion model implementation focused on the inference process, using a pre-trained U-Net backbone:
- Forward Process: A fixed process that sequentially adds Gaussian noise to images over T timesteps
- Reverse Process: A learned denoising process that iteratively removes noise, using the U-Net to predict the noise component at each step

Sampling Strategies and Classification Results
Two sampling approaches were implemented and evaluated:
Performance Comparison:
- DDPM: FID 34.73, Slow sampling (1000 steps), +4.1% classification gain
- DDIM: FID 38.32, Fast sampling (100 steps), +3.7% classification gain


Key Findings and Analysis
Quality vs. Utility Correlation
A strong correlation exists between generative quality (FID score) and classification utility:
- Diffusion models achieve both the best FID scores and highest classification gains
- Higher quality synthetic data translates directly to better downstream performance
- Training stability of generative models correlates with consistent augmentation benefits
Low-Data Amplification Effect
Synthetic data provides exponentially higher benefits in data-scarce scenarios:
- 10% real data: +12.9% improvement (largest gain)
- 100% real data: +4.1% improvement (still significant)
This finding has important implications for real-world applications where labeled data is expensive or limited.
Model Complementarity
Combining synthetic data from multiple generative models (+4.8% total gain) outperforms any single model, suggesting that different architectures capture complementary aspects of the data distribution.
Key Contributions
This research project demonstrates end-to-end validation of synthetic data augmentation with significant technical contributions:
- Complete pipeline from generative model training to classification validation
- Quantitative validation of synthetic data utility through downstream tasks
- Multi-model comparison showing relative strengths of different generative approaches
- Low-data scenario analysis revealing amplified benefits in data-scarce regimes
- Implementation from scratch of three different generative architectures with custom loss functions and training strategies
Technologies & Skills Used
- Languages & Frameworks: Python, PyTorch, NumPy, scikit-learn, Tensorboard
- Deep Learning: GANs (Vanilla, LSGAN, WGAN-GP), VAEs with β-annealing, Diffusion Models (DDPM/DDIM)
- Computer Vision: Image Classification, ResNet-50, Data Augmentation, Transfer Learning
- Evaluation: FID score calculation, Classification metrics, Statistical validation
- Dataset: CUB-200-2011 fine-grained bird classification benchmark